AI Model Guide
Best AI Models in 2026: GPT, Claude, Gemini, and More Compared
A plain-language hub for comparing the best AI models and best LLMs in 2026, with guidance on coding fit, team adoption, budget tradeoffs, and how to choose between GPT, Claude, Gemini, and cheaper API paths.
Last reviewed July 4, 2026Record updated July 4, 2026Live now
First-wave model guides
Start with the hub for the market view, then move into the coding, team-fit, and API pricing pages that answer the next model choice.
Best AI Models for Coding in 2026
A coding-focused guide to the AI models developers are comparing on speed, reliability, tooling, and daily team fit.
Claude vs GPT vs Gemini: Which AI Model Fits Your Team?
A plain-language comparison for teams choosing between Claude, GPT, and Gemini across work quality, control, and rollout fit.
Cheapest AI Model APIs for Startups in 2026
A cost-first guide to low-priced AI model APIs, with a focus on startup budgets, fallback strategy, and price-sensitive product teams.
Weekly newsletter
Get the weekly AI model brief
One email each week on GPT, Claude, Gemini, open models, API pricing, and the product changes that affect builders and buyers.
This page is for readers who want a practical answer to one of the most common AI buying questions in 2026: which model should we use right now? In plain language, an LLM is the language model that powers tools like ChatGPT, Claude, and Gemini. If you are searching for the best AI models or best LLMs, the right choice depends on work type, budget, governance needs, and how much experimentation your team can absorb.
At a glance
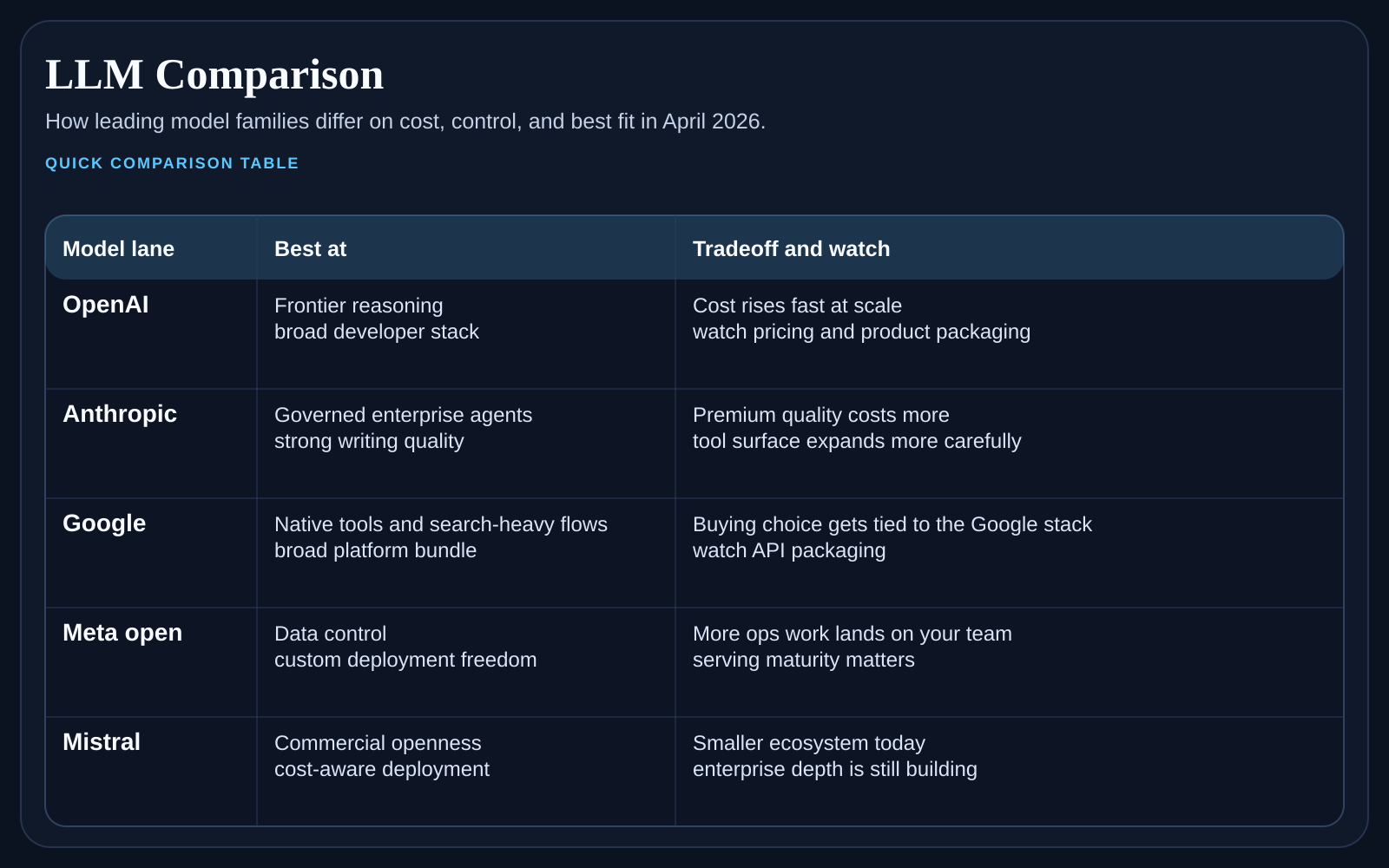
There is no single best AI model for every team. Premium frontier models can be worth the cost on hard reasoning or coding tasks. Lower-cost models can be better for tagging, routing, extraction, and product features where price and volume matter more than maximum depth on each call.
How to compare the best AI models in 2026
Start with the job to be done, not the logo. Coding, document analysis, chat support, and background extraction work reward different strengths.
Check the total serving plan, not only the list price. Routing, retries, and fallback paths can change the real economics fast.
Ask whether the team needs a consumer product experience, an API building block, or both.
Include governance and vendor fit in the evaluation if the model will touch sensitive workflows or regulated data.
Best AI models by team type
Product teams often need a flexible all-around model that balances quality, speed, and cost across many user-facing features.
Engineering teams often care more about coding quality, tool use, and how the model behaves across long debug sessions.
Enterprise buyers often care more about vendor fit, admin controls, support path, and procurement clarity than tiny output differences.
Cost-sensitive startups usually win with a mixed stack, not a single-model religion.
Use the right page for the real question
Go to Best AI Models for Coding in 2026 if software work is the deciding use case. Read Claude vs GPT vs Gemini: Which AI Model Fits Your Team? when the shortlist is already down to the big commercial vendors. Use Cheapest AI Model APIs for Startups in 2026 if price pressure and product margins are steering the conversation.
Why model decisions keep changing
The answer moves because model quality is only one part of the choice now. Packaging, rate limits, tool integration, enterprise controls, and cloud availability all shape what feels like the best option in practice. Teams should expect to revisit the shortlist as product packaging changes, not only when a major benchmark lands.
FAQ
What are the best AI models for most teams?
Most teams should start with a short list of strong general-purpose models, then narrow by workload. The best AI model for a product team, coding team, or budget-sensitive startup is often different once cost, tooling, and governance are part of the decision.
Should most teams standardize on one model family?
Many teams eventually do, but only after they understand their workload mix. Standardizing too early can trap simple tasks on an expensive route or push hard tasks onto a weak one.
What matters more, benchmark scores or packaging?
For real deployments, packaging often matters more than people expect. Rate limits, admin tools, integration paths, and price tiers can change the business answer fast.
How to use this cluster
Treat this hub as the orientation layer. Once you know whether your main concern is coding, team fit, or cost, move to the relevant child page and come back here when the market shifts. That is the fastest way to keep your model decision current without re-learning the whole category each month.