AI Coding Agent Guide
Claude Code vs Codex
A Claude Code vs Codex comparison for teams that care about repo control, long-running code tasks, review clarity, and how much structure the tool imposes on daily work.
Last reviewed May 16, 2026Record updated May 16, 2026Live now
Compare this next
Use the hub for the market view, then move across the sibling comparisons that answer the next tool choice your team will face.
If you are searching Claude Code vs Codex, you are usually deciding between two terminal-first AI coding tools that look similar from far away and feel different once real repo work starts. Both attract developers who want an AI tool close to the repo, close to the shell, and close to execution instead of an editor autocomplete layer.
At a glance
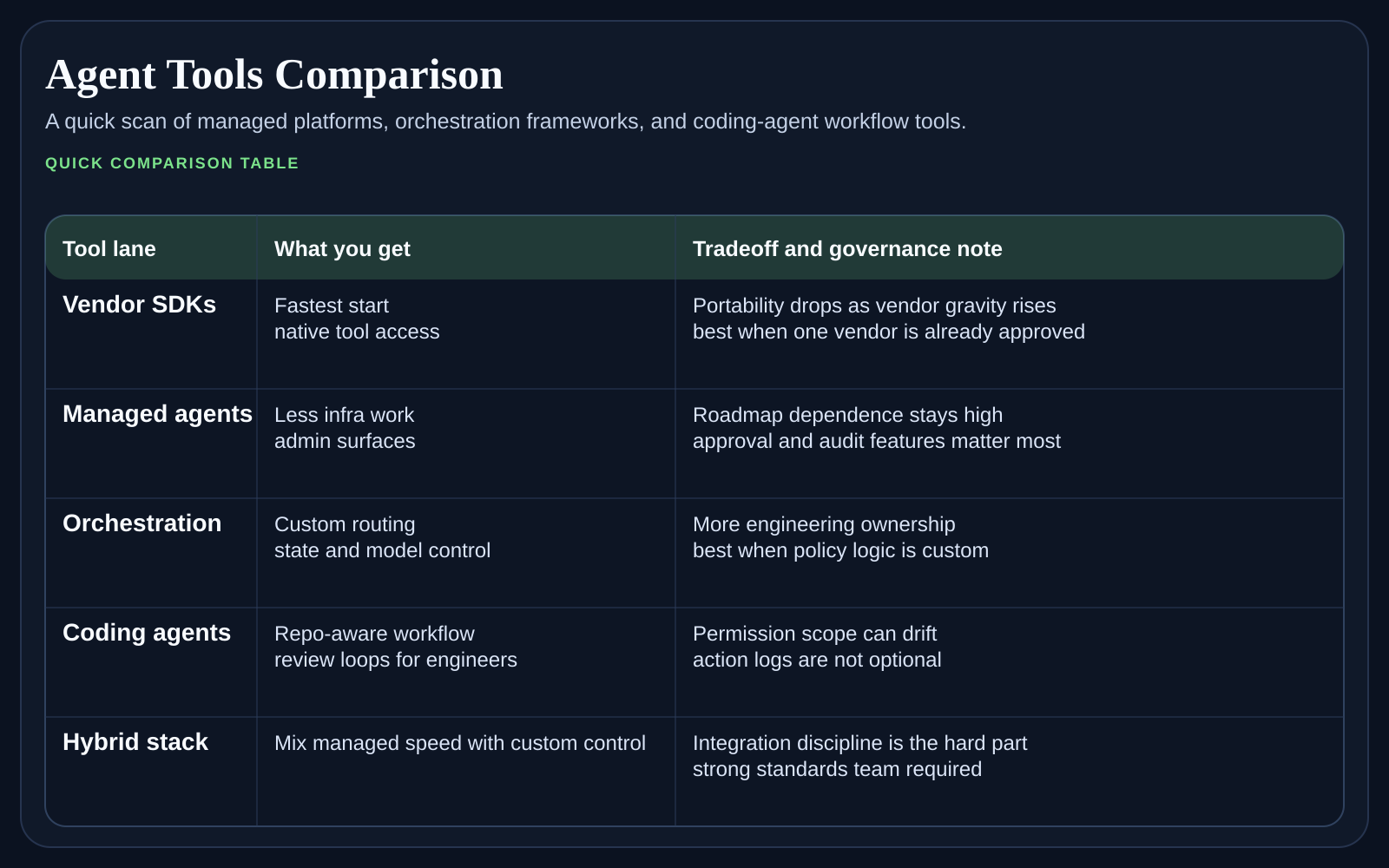
The best short answer is this. Choose the one that matches your appetite for structure. If your team wants a disciplined command-line agent flow with clear task boundaries, Codex usually gets the first look. If your team already prefers Anthropic tooling and values the way Claude handles long reasoning and text-heavy work, Claude Code can be the more natural fit.
Claude Code vs Codex, where Codex tends to stand out
Codex is appealing when teams want a crisp execution loop around commands, planning, and repo operations. It fits engineering groups that care about reproducibility, want the AI to stay legible inside normal development practices, and see the terminal as a feature rather than a tax.
Claude Code vs Codex, where Claude Code tends to stand out
Claude Code usually feels strongest for builders who like Anthropic models, value patient long-form reasoning, and want a coding tool that can stay useful when the task is still partly exploratory. It can be a good fit when coding work blends into debugging notes, design tradeoffs, and text-heavy investigation rather than pure code generation.
The choice usually turns on these four factors
Workflow shape. Ask whether the tool fits your existing shell, scripts, and test loop without constant adaptation.
Context behavior. Some teams care most about how the tool handles long repo sessions, file discovery, and changing instructions over time.
Vendor alignment. If your organization already leans toward OpenAI or Anthropic for policy, billing, or model preferences, that can simplify adoption.
Reviewer trust. The stronger tool is the one whose outputs your team can inspect and accept with less confusion.
Which teams usually choose each
Codex tends to fit teams that want a more explicit execution loop and like seeing planning, commands, and repo operations as part of the workflow.
Claude Code tends to fit teams that expect coding work to blend with long reasoning, investigation, and text-heavy problem solving.
If vendor alignment is the main driver, say that openly. It is better to admit a stack preference than pretend tiny output differences made the decision.
If reviewer trust is uncertain for both, keep the pilot going until the review burden becomes obvious in real work.
How to run a fair pilot
Use the same repo slice, the same acceptance criteria, and the same review standard for both tools. Measure not only speed, but also rework, test stability, and how often the engineer needs to intervene because the tool drifted from the task. The winning product is often the one that creates fewer messy second-order problems rather than the one that writes the flashiest first draft.
FAQ
What is the main difference in Claude Code vs Codex?
The main difference is workflow feel. Codex usually pushes a clearer execution loop around commands and repo operations, while Claude Code often feels more comfortable when the task blends code with longer investigation and text-heavy reasoning.
Does terminal-first always mean more advanced?
Not necessarily. It often means the tool gives the user more direct control over execution. That can be more powerful for some teams and more demanding for others.
Should we standardize on the same model vendor as the coding tool?
Only if it reduces real operational friction. Shared billing or policy can help, but it should not override a clear workflow mismatch.
Where this comparison fits in the cluster
If your team is comparing products across very different autonomy levels, go back to OpenAI Codex vs Cursor vs Devin. If the debate is whether you need a terminal tool at all, step out to Best AI Coding Agents in 2026 and decide whether editor-first software would be enough.
Weekly newsletter
Get the weekly AI coding tools brief
One email each week on Copilot, Cursor, Codex, Claude Code, pricing changes, and rollout moves that affect engineering teams.